A lot has been written on the importance of a portfolio if you are looking for a DataScience role. Ideally, you should document your learning journey so that you can reuse code, write well-documented code and also improve your data storytelling skills.

However, most students and beginners get stumped on what to include in their portfolio, as their projects are all the same that their classmates, bootcamp associates and seniors have created. So, in this post I am going to tell you what projects you should have in your portfolio kitty, as well as a list of ideas that you can use to construct a collection of projects that will help you stand out on LinkedIn, Github and in the eyes of prospective hiring managers.

You can find many interesting projects on the “Projects” page of my website JourneyofAnalytics. I’ve also listed 50+ sources for free datasets in this blogpost.
In this post though, I am classifying projects based on skill level along with sample ideas for DIY projects that you can attempt on your own.
On that note, if you are already looking for a job, or about to do so, do take a look at my book “DataScience Jobs“, available on Amazon. This book will help you reduce your job search time and quickly start a career in analytics.
Since I prefer R over Python, all the project lists in this post will be coded in R. However, feel free to implement these ideas in Python, too!
a. Entry-level / Rookie Stage
- If you are just starting out, and are not very comfortable with even syntax, your main aim is to learn how to code along with DataScience concepts. At this stage, just try to write simple scripts in R that can pull data, clean it up and calculate mean/median and create basic exploratory graphs. Pick up any competition dataset on Kaggle.com and look at the highest voted EDA script. Try to recreate it on your own, read through and understand the hows and whys of the code. One excellent example is the Zillow EDA by Philipp Spachtholz.
- This will not only teach you the code syntax, but also how to approach a new dataset and slice/dice it to identify meaningful patterns before any analysis can begin.
- Once you are comfortable, you can move on to machine learning algorithms. Rather than Titanic, I actually prefer the Housing Prices Dataset. Initially, run the sample submission to establish a baseline score on the leaderboard. Then apply every algorithm you can look up and see how it works on the dataset. This is the fastest way to understand why some algorithms work on numerical target variables versus categorical versus time series.
- Next, look at the kernels with decent leaderboard score and replicate them. If you applied those algorithms but did not get the same result, check why there was a mismatch.
- Now pick a new dataset and repeat. I prefer competition datasets since you can easily see how your score moves up or down. Sometimes simple decision trees work better than complex Bayesian logic or Xgboost. Experimenting will help you figure out why.
Sample ideas –
- Survey analysis: Pick up a survey dataset like the Stack overflow developer survey and complete a thorough EDA – men vs women, age and salary correlation, cities with highest salary after factoring in currency differences and cost of living. Can your insights also be converted into an eye-catching Infographic? Can you recreate this?
- Simple predictions: Apply any algorithms you know on the Google analytics revenue predictor dataset. How do you compare against the baseline sample submission? Against the leaderboard?
- Automated reporting: Go for end-to-end reporting. Can you automate a simple report, or create a formatted Excel or pdf chart using only R programming? Sample code here.
b. Senior Analyst/Coder
- At this stage simple competitions should be easy for you. You dont need to be in the top 1%, even being in the Top 30-40% is good enough. Although, if you can win a competition even better!
- Now you can start looking at non-tabular data like NLP sentiment analysis, image classification, API data pulls and even dataset mashup. This is also the stage when you probably feel comfortable enough to start applying for roles, so building unique projects are key.
- For sentiment analysis, nothing beats Twitter data, so get the API keys and start pulling data on a topic of interest. You might be limited by the daily pull limits on the free tier, so check if you need 2 accounts and aggregate data over a couple days or even a week. A starter example is the sentiment analysis I did during the Rio Olympics supporting Team USA.
- You should also start dabbling in RShiny and automated reports as these will help you in actual jobs where you need to present idea mockups and standardizing weekly/ daily reports.
Sample ideas –
- Twitter Sentiment Analysis: Look at the Twitter sentiments expressed before big IPO launches and see whether the positive or negative feelings correlated with a jump in prices. There are dozens of apps that look at the relation between stock prices and Twitter sentiments, but for this you’d need to be a little more creative since the IPO will not have any historical data to predict the first day dips and peaks.
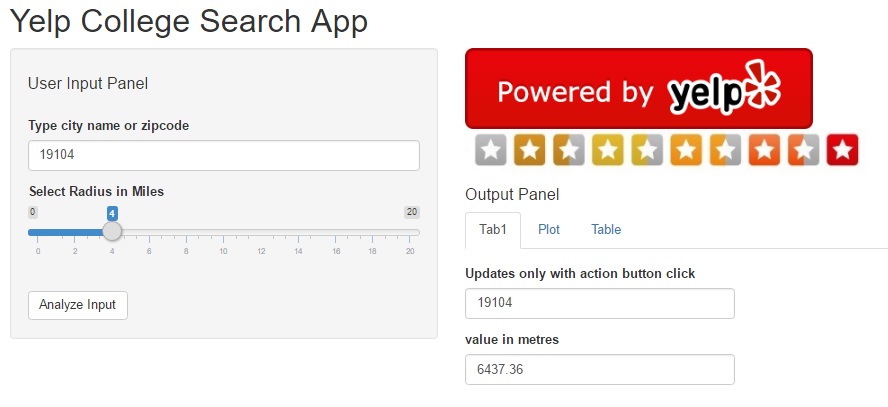
- API/RShiny Project: Develop a RShiny dashboard using Yelp API, showing the most popular restaurants around airports. You can combine a public airport dataset and merge it with filtered data from the Yelp API. A similar example (with code) is included in this Yelp College App dashboard.
- Lyrics Clustering: Try doing some text analytics using song lyrics from this dataset with 50,000+ songs. Do artists repeat their lyrics? Are there common themes across all artists? Do male singers use different words versus female solo tracks? Do bands focus on a totally different theme? If you see your favorite band or lead singer, check how their work has evolved over the years.
- Image classification starter tutorial is here. Can you customize the code and apply to a different image database?
c. Expert Data Scientist
- By now, you should be fairly comfortable with analyzing data from different datasource types (image, text, unstructured), building advanced recommender systems and implementing unsupervised machine learning algorithms. You are now moving from analyze stage to build stage.
- You may or may not already have a job by now. If you do, congratulations! Remember to keep learning and coding so you can accelerate your career further.
- If you have not, check out my book on how to land a high-paying ($$$) Data Science job job within 90 days.
- Look at building Deep learning using keras and apps using artificial intelligence. Even better, can you fully automate your job? No, you wont “downsize” yourself. Instead your employer will happily promote you since you’ve shown them a superb way to improve efficiency and cut costs, and they will love to have you look at other parts of the business where you can repeat the process.
Sample project ideas –
- Build an App: College recommender system using public datasets and web scraping in R. (Remember to check terms of service as you do not want to violate any laws!) Goal is to recreate a report like the Top 10 cities to live in, but from a college perspective.
- Start thinking about what data you need – college details (names, locations, majors, size, demographics, cost), outlook (Christian/HBCU/minority), student prospects (salary after graduation, time to graduate, diversity, scholarship, student debt ) , admission process (deadlines, average scores, heavy sports leaning) and so on. How will you aggregate this data? Where will you store it? How can you make it interactive and create an app that people might pay for?
- Upwork Gigs: Look at Upwork contracts tagged as intermediate or expert, esp. the ones with $500+ budgets. Even if you dont want to bid, just attempt the project on your own. If you fail, you will know you still need to master some more concepts, if you succeed then it will be a superb confidence booster and learning opportunity.
- Audio Processing: Use the VOX celebrity dataset to identify the speaker based on audio/speech dataset. Audio files are an interesting datasource with applications in customer recognition (think bank call centers to prevent fraud), parsing for customer complaints, etc.
- Build your own package: Think about the functions and code you use most often. Can you build a package around it? The most trending R-packages are listed here. Can you build something better?
Do you have any other interesting ideas? If so, feel free to contact me with your ideas or send me a link with the Github repo.

