In the last few posts, we saw standalone analytics projects to perform sentiment analysis, visually explore large datasets for insights and create interesting Shiny applications.
In the coming months however, we will cover how to implement machine learning algorithms in depth. We will explore the underlying concepts behind the algorithm, (why and how the formula works) , implement using a real-world Kaggle dataset and also learn about limitations and advantages.
What algorithms will we cover?
There are many algorithms to choose from, and this infographic from ThinkBigData provides an excellent and comprehensive list. Feel free to use as a handout or print one for your cubicles! For our purposes, we will cover two algorithms from each category.

Categories of machine learning algorithms. Source – ThinkBigData.com, by author Anubhav Srivastava.
Quick FAQ – selecting algorithm in practice
Many readers often ask, “how do I understand which algorithm to select? ” And this is also where new programmers often get stuck.
The long-winded answer is there is no secret sauce, and unfortunately often comes from experience or the problem definition itself.
The above answer is not very satisfying, so here are two “cheat-sheet” answers:
- A good approximation is given by this infographic by Microsoft Azure is a great example. Download it from Link here.
- Regression is a very common and flexible model, so the table below provides idea to create a base model based on whether your target variable is qualitative (numeric) or categorical (e.g gender or country)
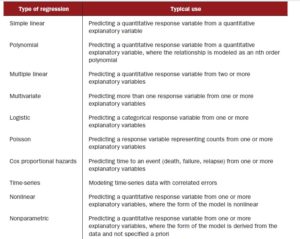
regression algorithms based on target variables
