In this tutorial, we will explore the open roles at Google, and try to see what common attributes Google is looking for, in future employees.
This dataset comes from the Kaggle site, and contains text information about job location, title, department, minimum and preferred qualifications and the responsibilities of the position. Using this dataset we will try to answer the following questions: You can download the dataset here, and run the code on the Kaggle site itself here.
- Where are the open roles?
- Which departments have the most openings?
- What are the minimum and preferred educational qualifications needed to get hired at Google?
- How much experience is needed?
- What categories of roles are the most in demand?
Data Preparation and Cleaning:
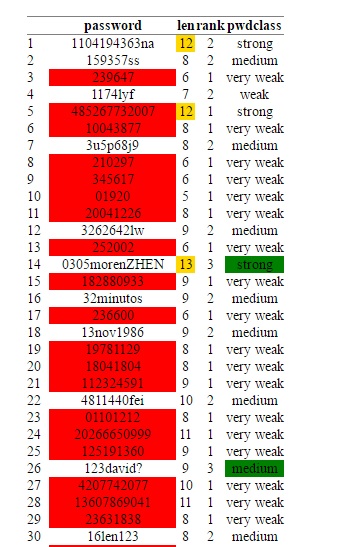
The data is all in free-form text, so we do need to do a fair amount of cleanup to remove non-alphanumeric characters. Some of the job locations have special characters too, so we remove those using basic string manipulation functions. Once we read in the file, this is the snapshot of the resulting dataframe:

Job Categories:
First we look at which departments have the most number of open roles. Surprisingly, there are more roles open for the “Marketing and Communications” and “Sales & Account Management” categories, as compared to the traditional technical business units. (like Software Engineering or networking) .

Full-time versus internships:
Let us see how many roles are full-time and how many are for students. As expected, only ~13% of roles are for students i.e. internships. Majority are full-time positions.

Technical Roles:
Since Google is predominantly technical company, let us see how many positions need technical skills, irrespective of the business unit (job category)
a) Roles related to “Google Cloud”:
To check this, we investigate how many roles have the phrase either in the job title or the responsibilities. As shown in the graph below, ~20% of the roles are related to Cloud infrastructure, clearly showing that Google is making Cloud services a high priority.

Educational Qualifications:
Here we are basically parsing the “min_qual” and “pref_qual” columns to see the minimum qualifications needed for the role. If we only take the minimum qualifications into consideration, we see that 80% of the roles explicitly ask for a bachelors degree. Less than 5% of roles ask for a masters or PhD.
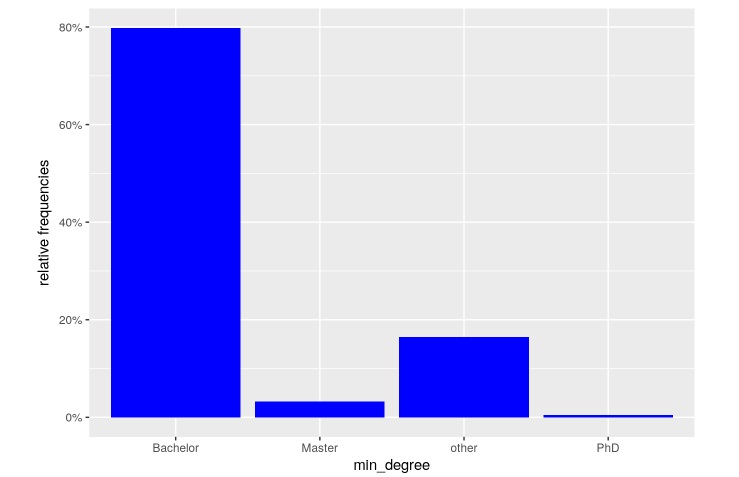
However, when we consider the “preferred” qualifications, the ratio increases to a whopping ~25%. Thus, a fourth of all roles would be more suited to candidates with masters degrees and above.

Google Engineers:
Google is famous for hiring engineers for all types of roles. So we will read the job qualification requirements to identify what percentage of roles requires a technical degree or degree in Engineering.
As seen from the data, 35% specifically ask for an Engineering or computer science degree, including roles in marketing and non-engineering departments.
Years of Experience:
We see that 30% of the roles require at least 5-years, while 35% of roles need even more experience.
So if you did not get hired at Google after graduation, no worries. You have a better chance after gaining a strong experience in other companies.

Role Locations:
The dataset does not have the geographical coordinates for mapping. However, this is easily overcome by using the geocode() function and the amazing Rworldmap package. We are only plotting the locations, so some places would have more roles than others. So, we see open roles in all parts of the world. However, the maximum positions are in US, followed by UK, and then Europe as a whole.

Responsibilities – Word Cloud:
Let us create a word cloud to see what skills are most needed for the Cloud engineering roles: We see that words like “partner”, “custom solutions”, “cloud”, strategy“,”experience” are more frequent than any specific technical skills. This shows that the Google cloud roles are best filled by senior resources where leadership and business skills become more significant than expertise in a specific technology.

Conclusion:
So who has the best chance of getting hired at Google?
For most of the roles (from this dataset), a candidate with the following traits has the best chance of getting hired:
- 5+ years of experience.
- Engineering or Computer Science bachelor’s degree.
- Masters degree or higher.
- Working in the US.
The code for this script and graphs are available here on the Kaggle website. If you liked it, don’t forget to upvote the script. 🙂
Thanks and happy coding!