In this blogpost we are going to implement dashboards using R programming, using the latest R library package “flexdashboard”.
R programming already offers some good features for graphs and charts (packages like ggplot, leaflet, etc). Plus there is always the option to create web applications using the Shiny library and presentations with RMarkdown documents.
However, this new library leverages these libraries and allows us to create some stunning dashboards, using interactive graphs and text. What I loved the most, was the “storyboard” feature that allows me to present content in Tableau-style frames. Please note that for this you need to create RMarkdown (.Rmd) files and insert the code using the R chunks as needed.
Do I think it will replace Tableau or any other enterprise BI dashboard tool? Not really (at least in the near future). But I do think it offers the following advantages:
- great alternative to static presentations since your audience can interact with the data.
- RMarkdown allows both programming and regular text content to be pooled together in a single document.
- Open source (a very big plus, in my opinion!)
- Storyboard format allows you to logically move the audience through the analysis : problem statement, raw data and exploration, different parts of the models/simulations/ number crunching, patterns in data, final summary and recommendations. Presenting the patterns that allow you to accept or reject a hypothesis has never been easier.
So, without further ado, let us look at the dashboard implementation with two examples:
- Storyboard dashboard.
- Simple dashboard with Shiny elements.
Library Installation instructions:
To start off, please install the “flexdashboard” package in your RStudio IDE. If installation is completed correctly, you will see the flex-dashboard feature when you create a new RMarkdown document, as shown in images below:
Step1 image:

Step 2 image:

Storyboard Dashboard:
Instead of analyzing a single dataset, I have chosen to present different interactive graph types using the storyboard feature. This will allow you to experience the range of options possible with this package.
An image of the storyboard is shown below, but you can also view the live document here (without source code or data files) . The complete data and source code files are available for download here, simply search for “Dashboard Codefiles” on the Projects page.


The storyboard elements are described below:
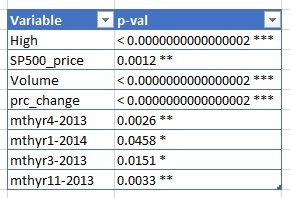
- Element 1 – Click on each frame to see the graph and explanation associated with that story point. (click element 5 to see Facebook stock trends)
- Element 2 – This is the location for your graphs, tables, etc. One below each story point.
- Element 3 – This explanation column in the right can be omitted, if required. However, my personal opinion is that this is a good way to highlight certain facts about the graph or place instructions, hyperlinks, etc. Like a webpage sidebar.
- Element 4 – My tutorial only has 4 story elements, but if you have more flexdashboard automatically provides left-right arrow for navigation. (Just like Tableau).
- Element 6 – Title bar for the project. Notice the social sharing button on the far right.
Shiny Style Simple Dashboard:
Here I have used Shiny elements to allow user to select the variables to plot on a graph. This also shows how you can divide your page into columns and rows, to show different content in different panes.
See image below for some of the features incorporated in this dashboard:

Feature explanation:
- Element 1 – Title pane. The red color comes from the “cerulean” theme I used. You can change colors to match your business logo or personal preferences.
- Element 2 – Shiny inputs. The dropdown is populated automatically from the dataset, so you don’t have to specify values separately.
- Element 3 – Output graph, based on choices from element 1.
- Element 4 – notice how this is separated vertically from element3, and horizontally from element 5.
- Element 5 – Another graph. You can render text, image or pull in web content using the appropriate Shiny commands.
- Element 6 – you can embed social share button, and also the source code. Click the code icon “</>” to view the code. You can also download the data and program files here, from my Projects page.
Hope you found these dashboard implementations useful. Please add your valuable comments and feedback in the comments section.
Until next time, happy coding! ?
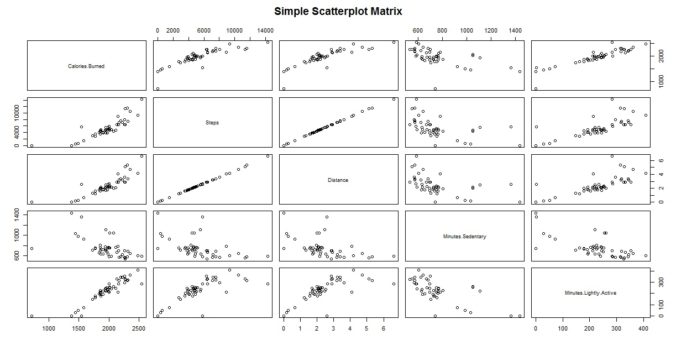
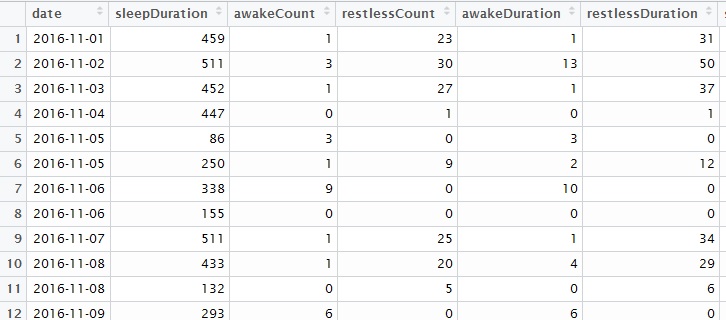

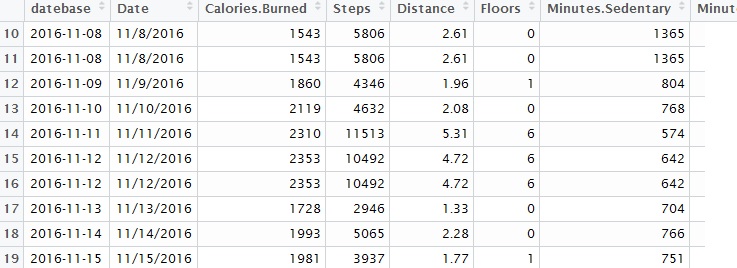
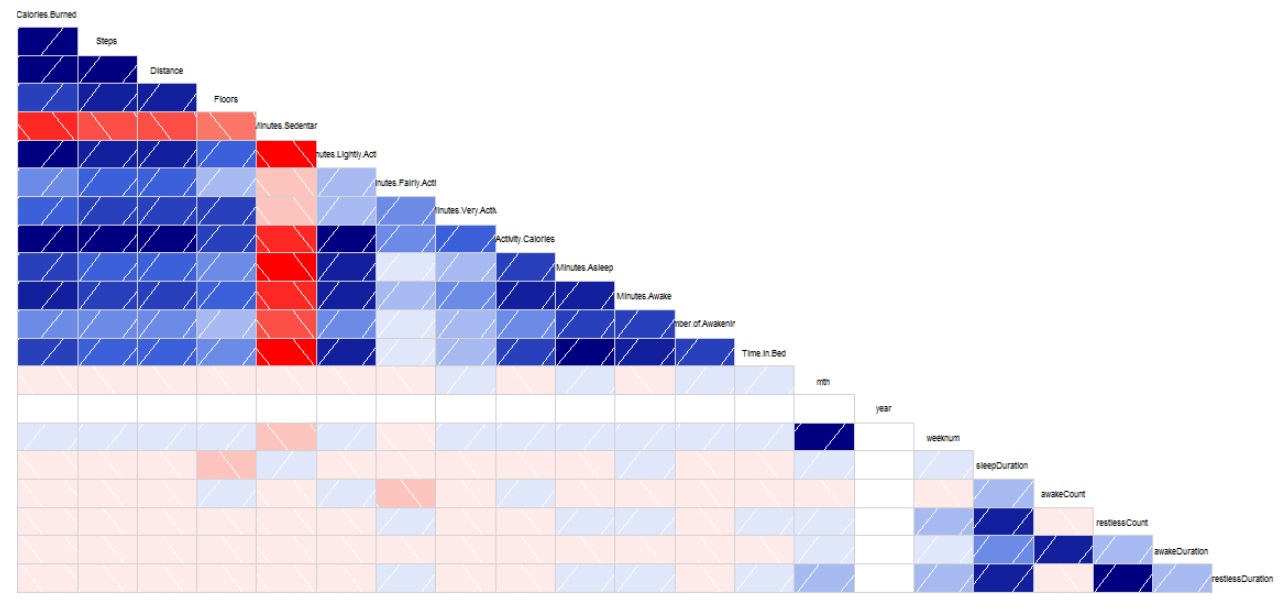
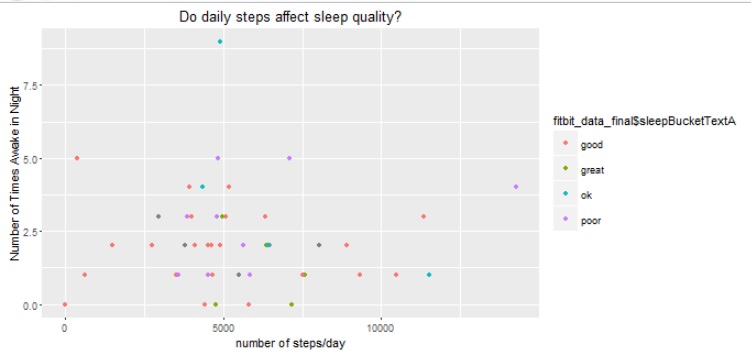
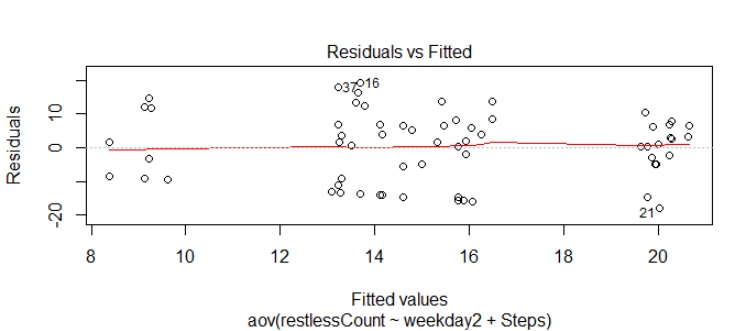
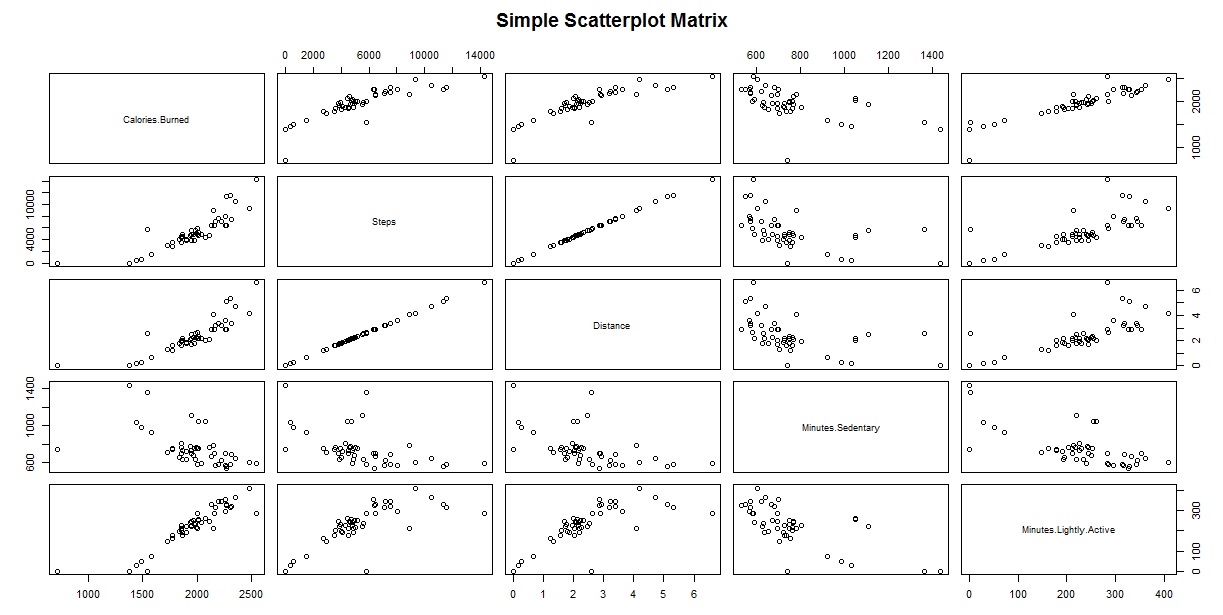
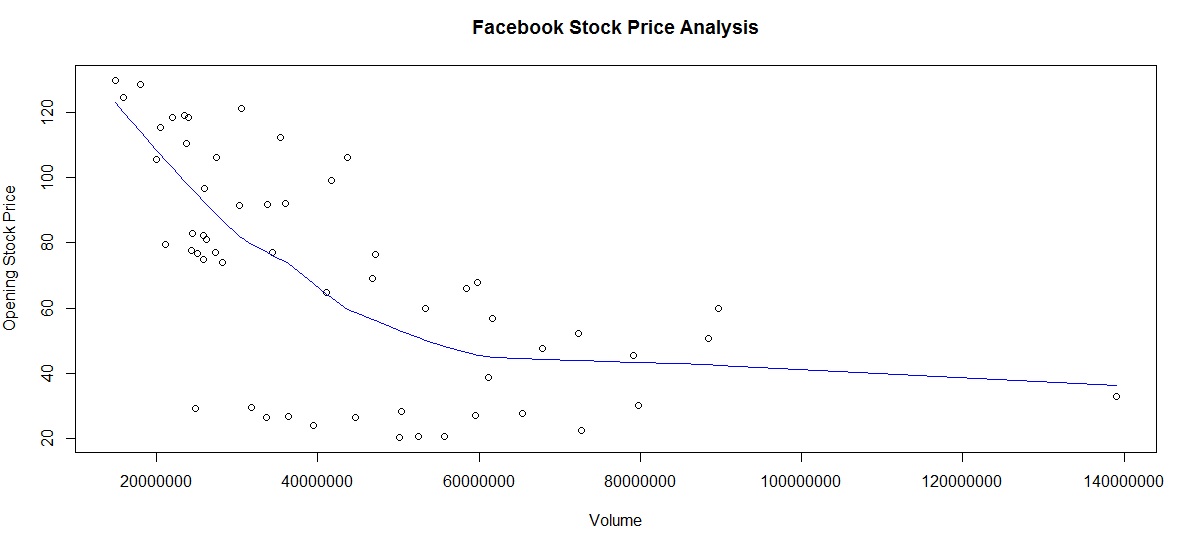
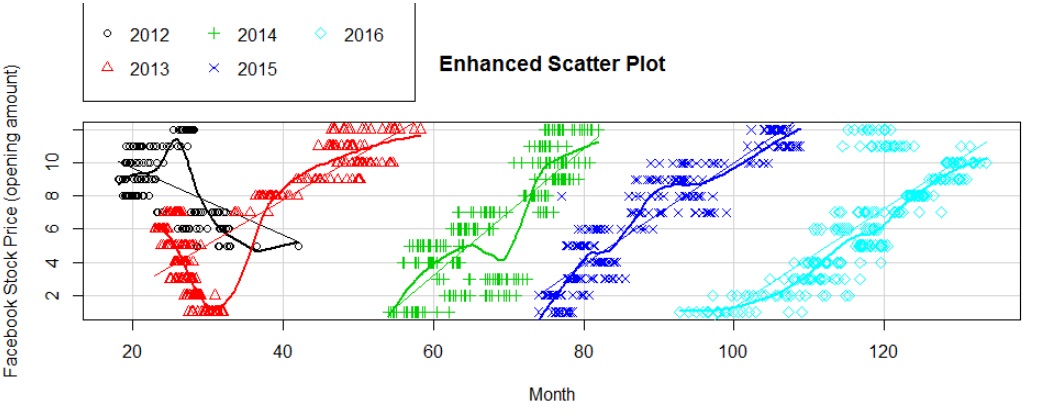
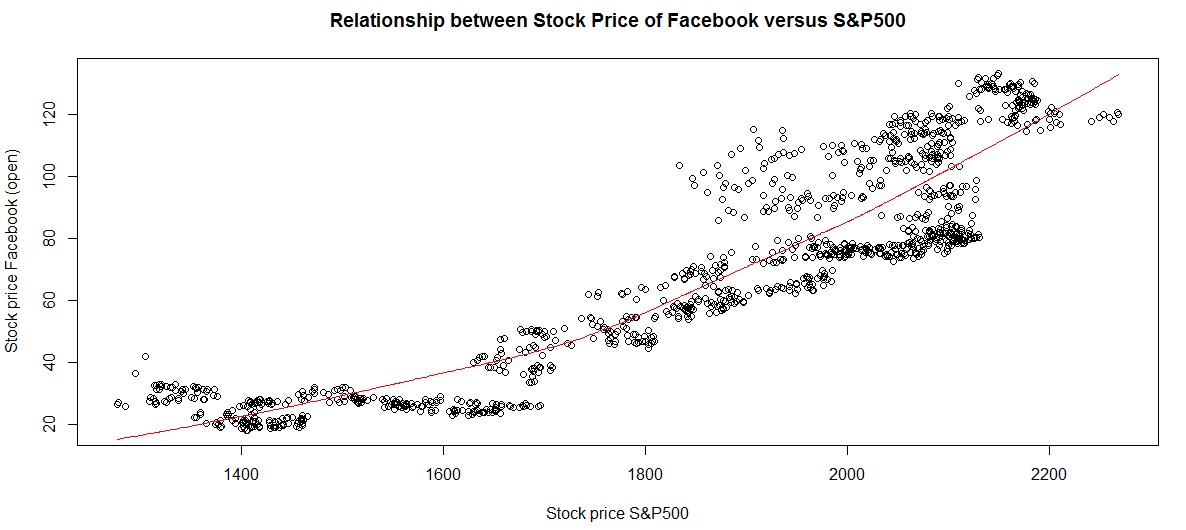
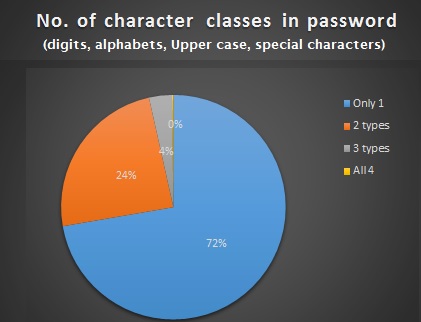
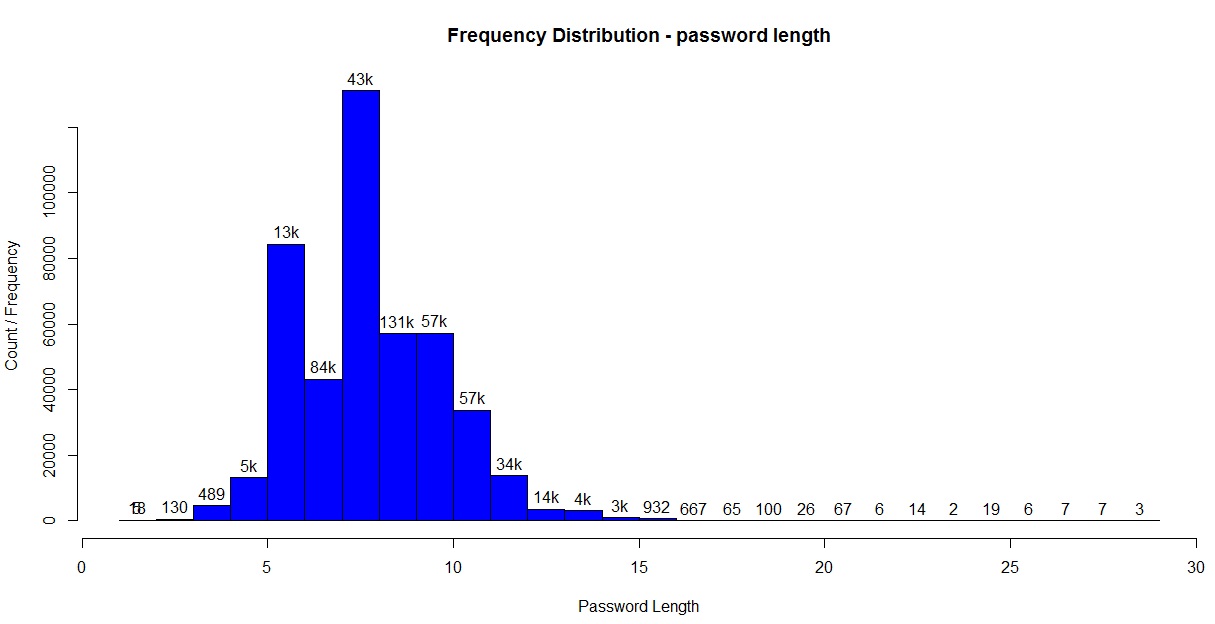
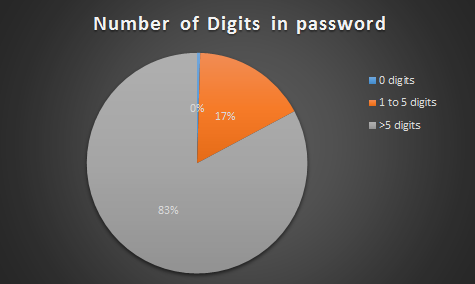
 Note, we use the sqldf package to aggregate data by monthyear / month for some of these charts.
Note, we use the sqldf package to aggregate data by monthyear / month for some of these charts.